Swift是谷歌提出的数据中心拥塞控制协议, 继承Timely的思想, 使用delay作为拥塞信号.
Core idea
- 区分 fabric congestion 和 endpoint congestion: 细粒度delay测量
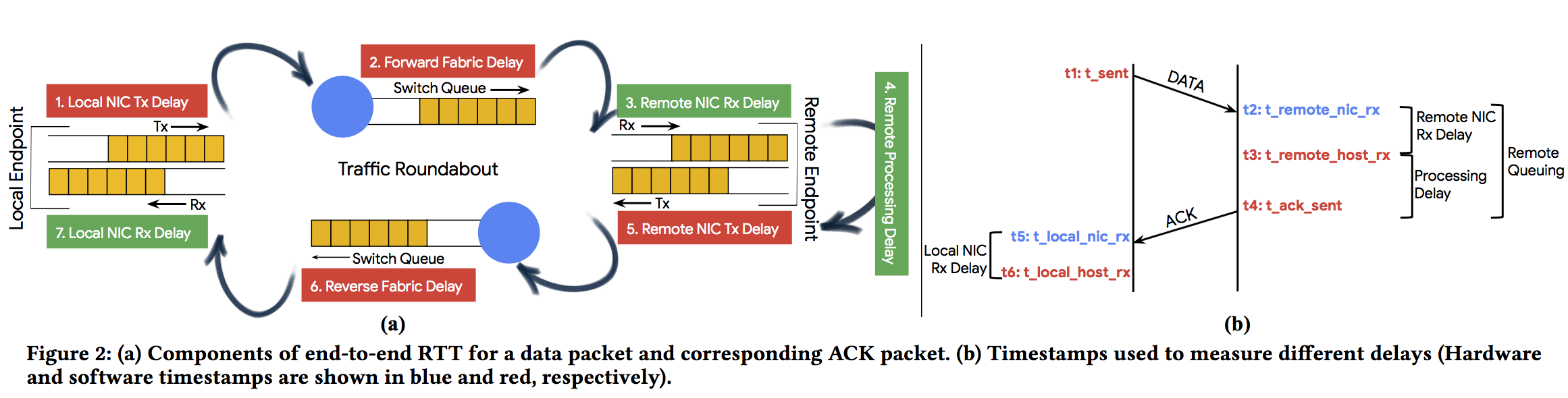
endpoint delay: remote-queuing (echoed in the ACK) + Local NIC Rx Delay (given by $t_{6}$ - $t_{5}$).
fabric delay: RTT - endpoint delay
- 使用Target Delay而不是delay gradient, 窗口演变仍使用AIMD原则
Design
- 针对fabric congestion 和 endpoint congestion, 维护两个拥塞窗口$fcwnd$ 和 $ecwnd$, 均使用以下算法调整窗口(算法中参数target delay不同), 最终的有效窗口为$min(fcwnd, ecwnd)$.

-
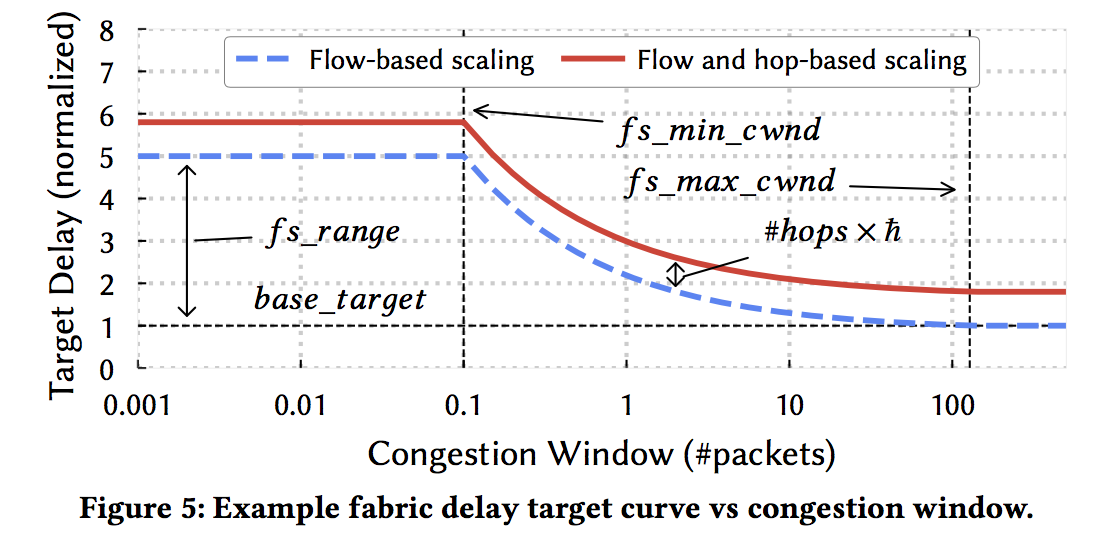
如何确定 fabirc target delay
Flow-based Scaling and Topology-based Scaling
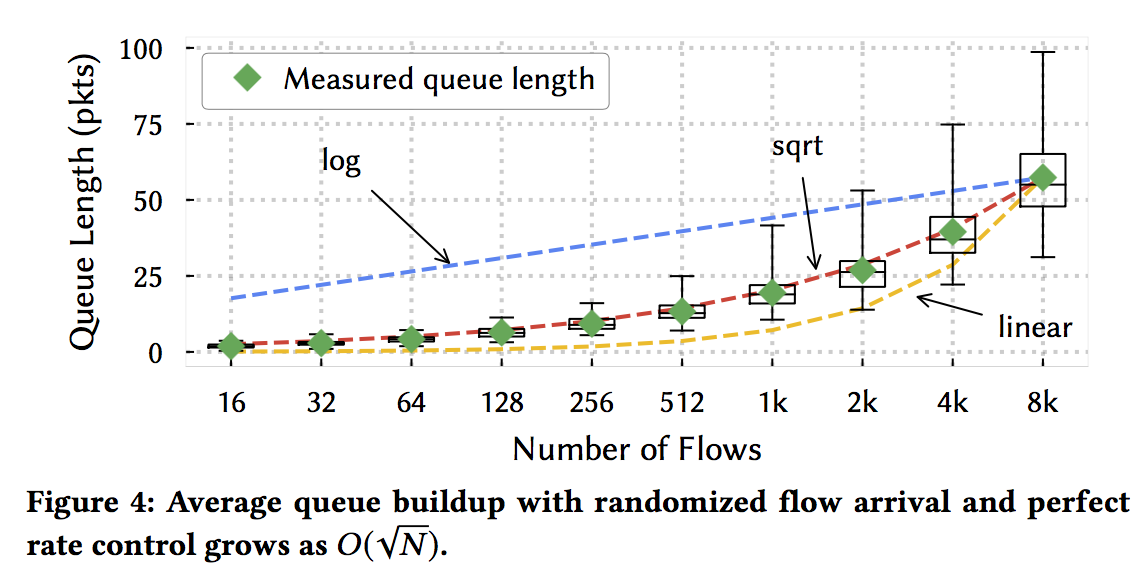
Estimate N: cwnd is inversely proportional to the number of flows when Swift has converged to its fair-share.
Basic Rule: adjust the target in proportion to $1/\sqrt{cwnd}$, i.e., the target delay grows as cwnd becomes smaller.
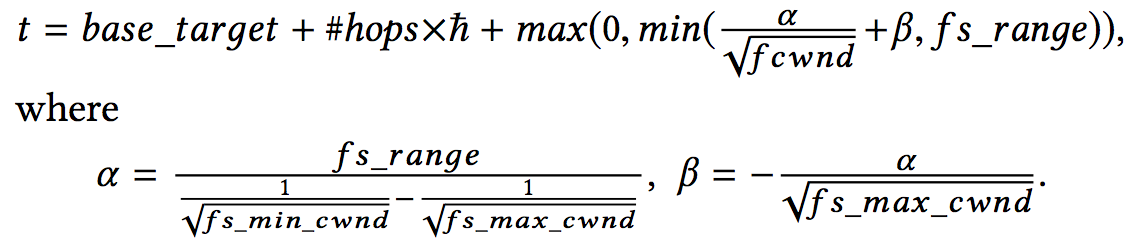
Implementation and Evaluation
Swift在Snap上实现, 一种kernal bypass 的 stack. 论文没有对如何从网卡获取timestamp进行详细介绍
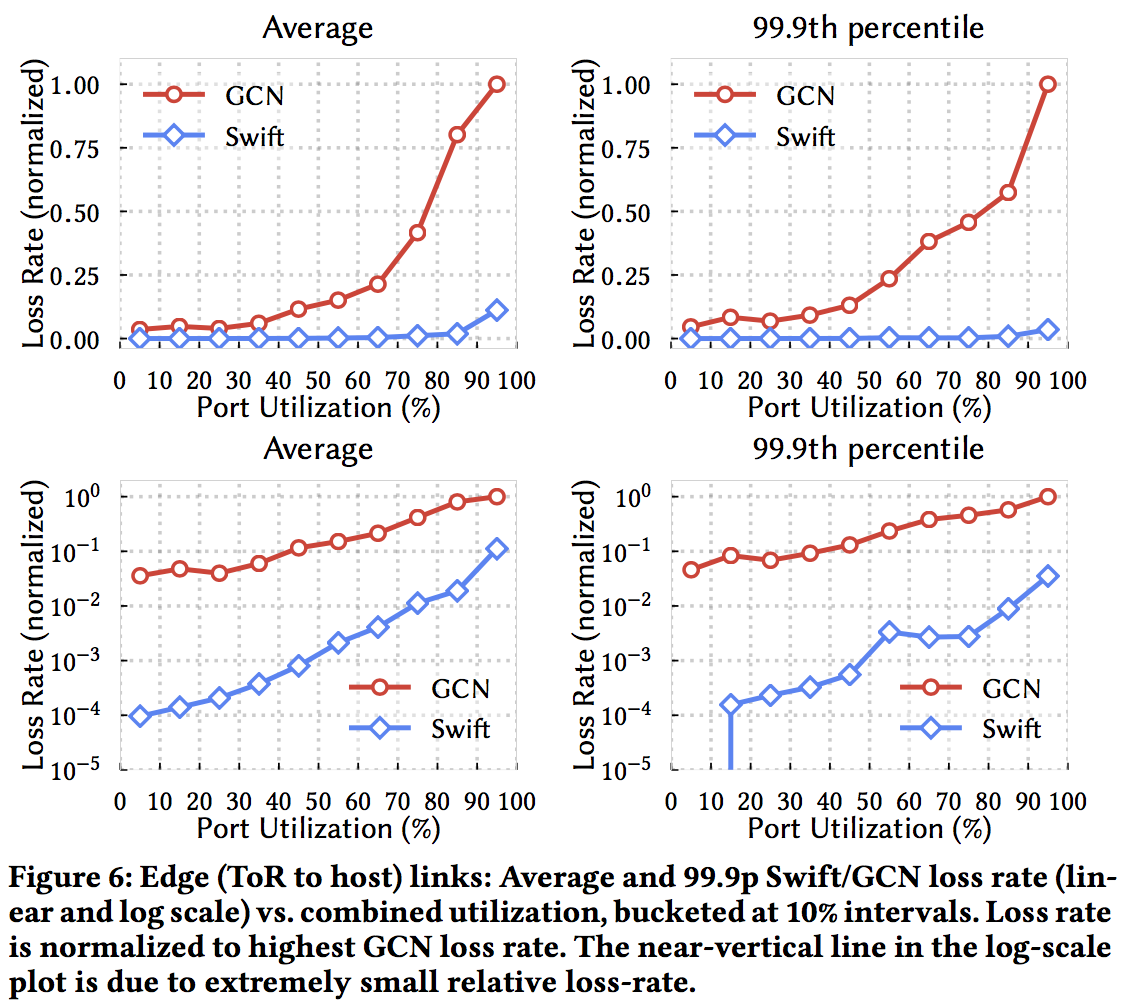
全部的实验在google的cluster完成, 按照论文作者的说法Swift已经在Google数据中心运行了接近四年, 已经经过了工业实际部署的检验, 能够显著降低丢包, 保持吞吐的同时降低延时.
实验主要与DCTCP比较(关注已经能够大规模部署的算法). 在Google数据中心DCTCP的实际落地方案是GCN.
Thoughts
读完此文, 个人觉得Google的工作很扎实, 仍然很有特色:
- 工业界非常强调可部署性, 希望能够只利用delay这个只需要网卡测量就可以获得的metric, 从Timely开始, 沿着这一方向Google继续推进了一大步. Swift 能够与异质网络设备兼容;论文中说ECN的阈值在实际的工业实践中仍然需要经常tuning;
-
区分fabric congestion 和 endpoint congestion, 这个思想在之前的数据中心拥塞控制协议中没有强调 (就笔者所知, 只有一篇终端rate limiter 的工作提到endpoint congestion), 主要是因为仍然认为fabric congestion是拥塞的主要种类, fabric 的 congestion 对性能影响最大;但是随着网络带宽增加, 应用需求增高, endpoint congestion越来越不容忽视;
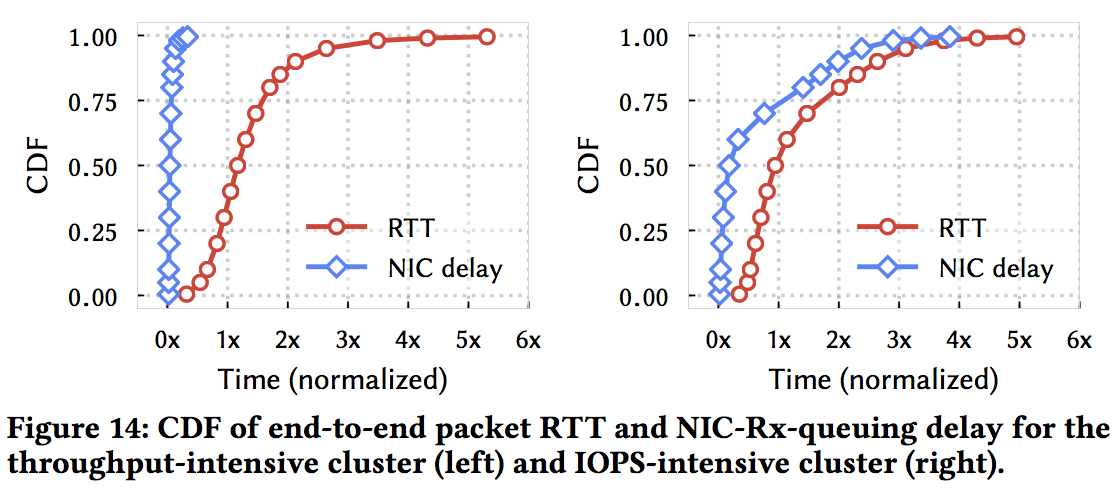
“Addressing host congestion has become critical to maintain low end-to-end queuing. Increasing line-rates and IOPS-intensive workloads stress software/hardware per-packet processing resources; CPU, DRAM bandwidth, and PCIe bottlenecks build up queues in NICs and host stacks”
- Scaling target delay的设计简洁有效
贴上几张作者的slides:




参考文献
Swift Delay is Simple and Effective for Congestion Control in the Datacenter