核心思想
rate limiting 与 priority value 相结合, 来保证 latency
Motivation
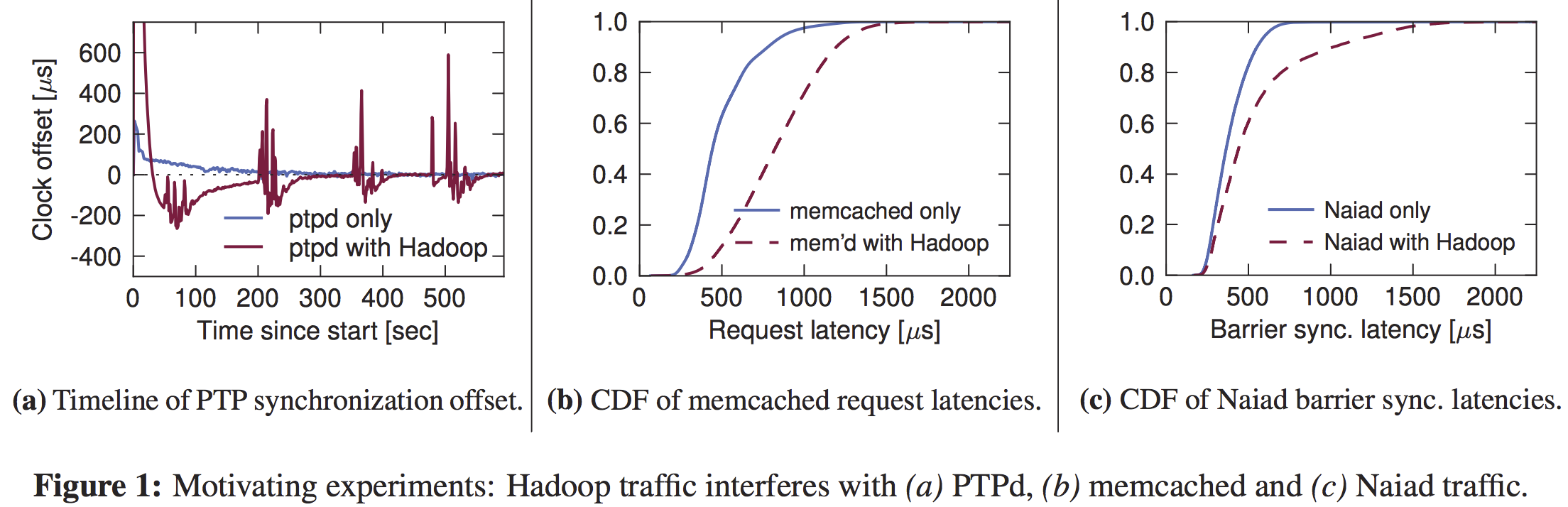
解决数据中心网络中 network interference 问题: congestion from throughput-intensive applications causes queueing that delays traffic from latency-sensitive applications.
实际上与DCTCP解决的问题有相似之处, latency来自于排队, 而大流占据队列使得小流的排队长, DCTCP通过减小queue长度来降低latency, 采用per-flow的拥塞控制+switch的ECN标记. QJUMP从应用的角度解决network interference来保证latency
Design
-
Single Switch Service Model
\[worst \ case \ end-to-end \ delay <= n \times \frac{P}{R} + \epsilon\]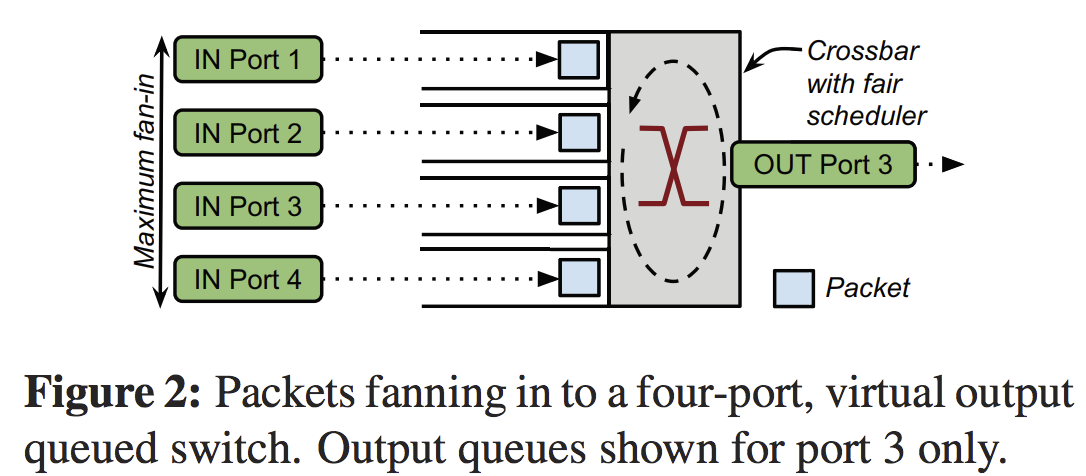
$P$ the maximum packet size (in bits), $R$ is the rate of the slowest link in bits per second and $\epsilon$ is the cumulative processing delay introduced by switch hops.
If we can find a bound for servicing delay, we can rate limit hosts so that they can never experience queueing dealy. -
Network epochs
A network epoch is the maximum time that an idle network will take to service one packet from every sending host, regardless of the source, destination or timing of those packets.
\[network \ epoch = 2n \times \frac{P}{R} + \epsilon\]每个host一个epoch只发一个包, 就能有latency的bound.由于时钟不同步,放宽后一个epoch应当是worst case end-to-end delay的两倍. -
QJUMP level
如果按照上式的所有host每个epoch发一个包, 随着host数目增多, 吞吐会下降. 对吞吐敏感的应用不友好.
\[throughput = \frac{P}{network \ epoch} \approx \frac{R}{2n}\]然而, 不同的应用对latency要求不同, 并且实际情况下, 不可能所有的host同时向一个目的端口发数据. 通过引入一个 factor $f$, 根据不同的应用放宽host的数目, 也就是引入QJUMP level. $f$ is a “throughput factor”: as the value of $f$ grows, so does the amount of bandwidth available.
\[n^{'} = \frac{n}{f}\]Use hardware priorities to run different QJump levels together, but isolated from each other.$f = 1$时, 一个epoch能发1个包保证latency; $f = n$时, 一个epoch能发$n$个包保证throughput. QJUMP level利用网络支持的优先级实现: For each priority, assign a distinct value of $f$ , with higher priorities receiving smaller values. Since a small value of $f$ implies an aggressive rate limit, priorities become useful because they are no longer “free”.
Experiments
- Testbed
-
Simulation
$P = 9kB$, $n = 144$, {$f_{0}$… $f_{7}$} = {144,100,20,10,5,3,2,1}
Thoughts
-
QJUMP实际上是对不同的优先级, 实施不同的速率limit.
高优先级的速率控制应当比低优先级的速率控制更加aggressive. -
在端进行rate limit实际上把网络中的排队一部分转移到了端的socket buffer中, QJUMP resizes socket buffers to apply early back-pressure. end-to-end latency实际上包括在端的排队latency以及网络中排队latency. 如果不resizes socket buffer可能会性能下降. 应用层 rate control 的重要性?
-
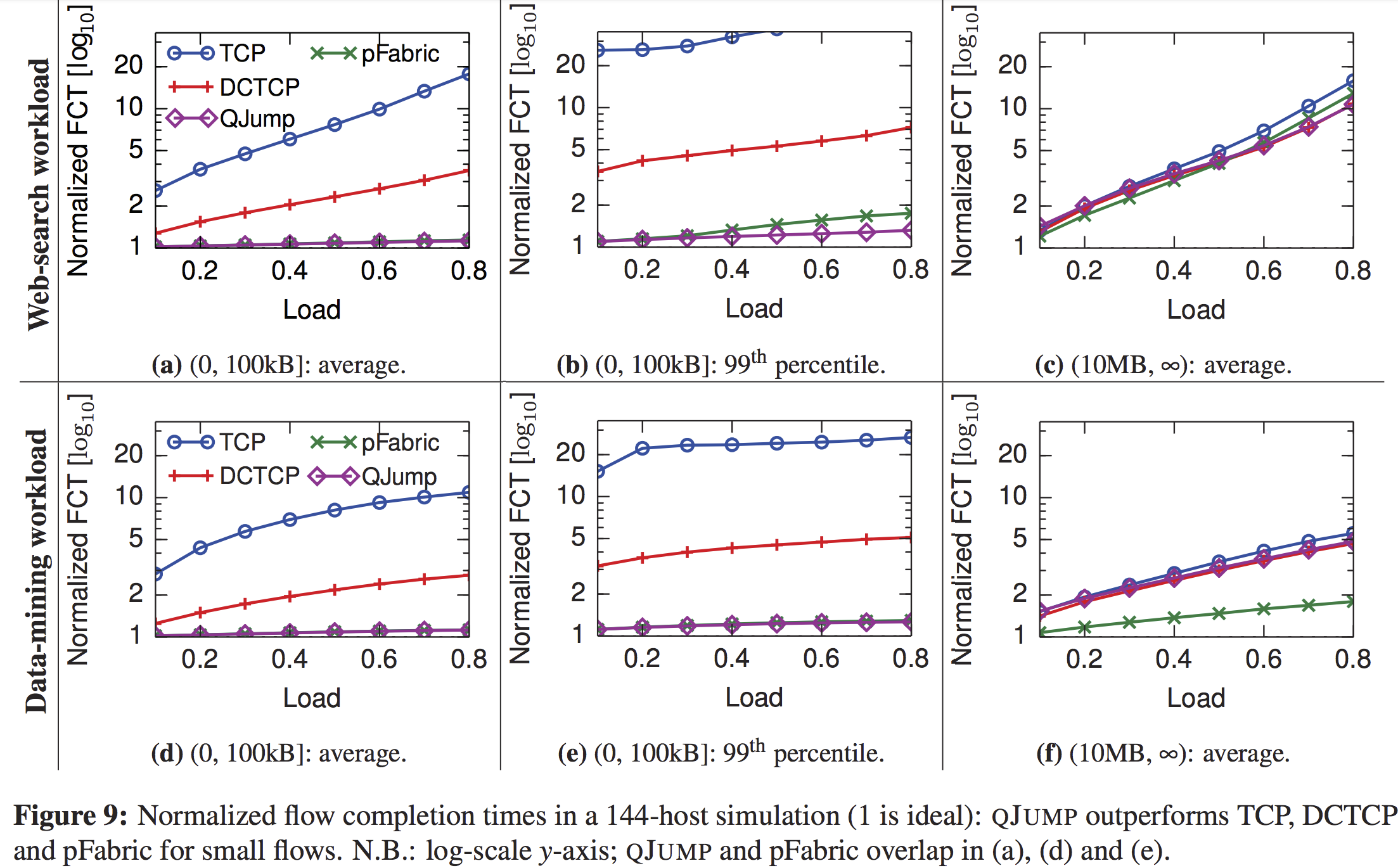
Figure 9(b), 结果中QJUMP比pfabric指标好, 说明了端速率控制的必要性?QJUMP对小流甚至能超过pfabric,但是大流不一定. Figure 9(f), between 30% and 63% worse than pFabric.
文中的解释:In the data-mining workload, 85% of all flows transfer fewer than 100kB, but over 80% of the bytes are transferred in flows of greater than 100MB (less than 15% of the total flows). QJUMP’s short epoch intervals cannot sense the difference between large flows, so it does not apply any rate-limiting (scheduling) to them. This results in sub-optimal behavior. A combined approach where QJUMP regulates interactions between large flows and small flows, while DCTCP regulates the interactions between different large flows might improve this.
-
优先级是针对应用的, 四层以上的, QJUMP解决的也是应用 interference的问题. DCTCP针对三层, 更加底层, 解决小流排队长