核心思想
分布式机器学习架构:Parameter Server. 首次将分布式参数服务器架构扩展到支持1000台服务器规模. A third generation open source implementation of a parameter server that focuses on the systems aspects of distributed inference.
Background
Machine Learning.
机器学习系统在 web search, spam detection, recommendation systems, computational advertising, and document analysis 有着广泛应用. 这些系统都是从examples中自动学习模型, 也就是 training data, 包括三个组成部分:feature extraction, the objective function, and learning.
Feature extraction 处理原始训练数据, 比如 documents, images and user query logs 来获得 feature vectors, 每一个feature就是训练数据的一个属性 (attribute). 对原始训练数据的 preprocessing 由已有的 MapReduce 等框架完成。
论文给了两类模型:Risk minimization(有监督算法一类,比如预测问题,降低预测错误率)和 Generative Models(无监督算法一类,比如从数据中提取主题,LDA算法).
Risk minimization:分布式梯度下降算法。样本 $x$ 预测值 $y$ (是否被点击). $x$可用许多属性描述, 每个属性有一个权重$w_{i}$. 学习目标:学习向量$w$. 则可根据$\sum_{i=1}^{d}x_{i}w_{i}$的值预测是否被点击. 损失函数$loss(x,y,w)$代表预测错误率,$\omega$用于惩罚模型的复杂度. 则最终的优化目标函数为:
\[F(W) = \sum_{i=1}^{n}loss(x_{i},y_{i},w_{i}) + \omega(w)\]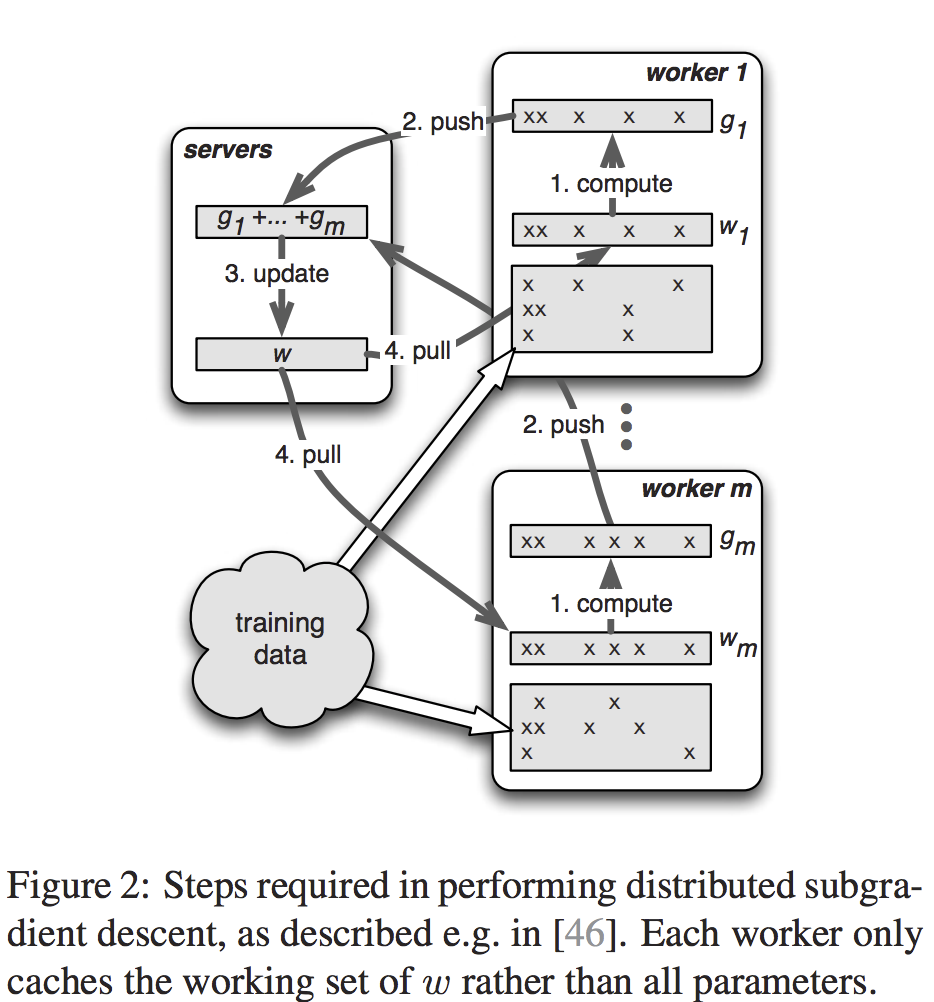
算法如下:

Challenges
-
Communication:每次模型更新都发送key value 开销大;通信同步带来barrier导致性能下降
-
Fault Tolerance:规模大 机器failure多
Design
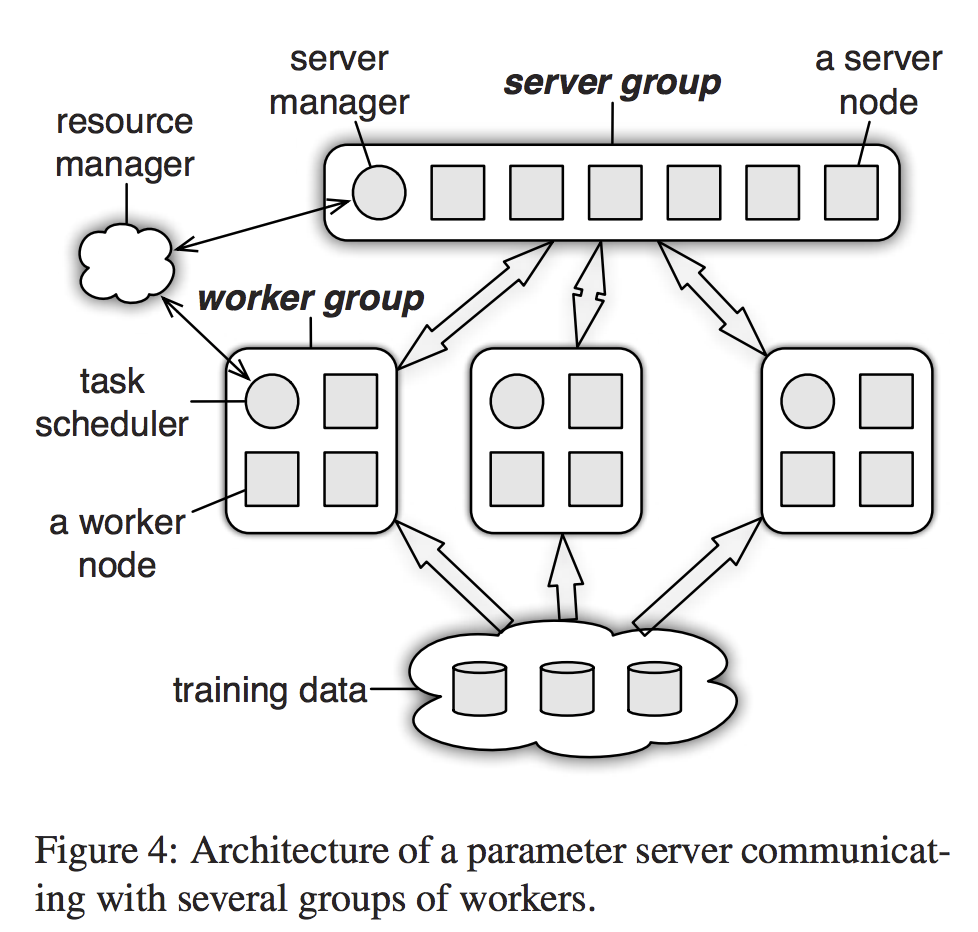
-
(Key,Value) Vectors
例如在前面的Risk minimization问题中,key:属性 value:对应的权重
-
Range Push and Pull
算法1中每个worker将它全部的梯度push给参数服务器,然后pull更新后的weight. Range Push and Pull指支持用户指定范围的push和pull. $w.push(R,dest)$ 指将在范围$R$中的key push给destination,destination可以是一个指定的node或一个node group(如server group).
-
Asynchronous Tasks and Dependency
一个task:a push or a pull that a
workerissues to servers. 或者仅仅是user-defined function that theschedulerissues to any node. 一个Task也可以有多个subtask,比如在算法1中 task WorkerIterate 中就包含一个pull task和一个push task.Task 是异步执行的:caller可以在issue一个task之后立即执行接下来的运算. caller收到callee的reply标记为task的完成. callee默认并行执行task,如果caller想要顺序执行task,则可以在task间加入
execute-after-finishdependency. -
Flexible Consistency
task的并行执行对提升系统性能有重要影响. 但是并行执行会带来node的数据不一致问题(有dependency的task间). 数据不一致问题会使得worker使用的不是最新的参数,算法收敛时间增加. 参数服务器架构提供了三种灵活的数据一致性模型:
(1)Sequential:所有task完全顺序执行. 也叫Bulk Synchronous Processing.
(2)Eventual:所有task都有可能同时开始执行. 只推荐用于对与delay不敏感的算法.
(3)Bounded Delay:设置一个最大delay时间$\tau$, 为新的task被前面的task阻塞的最大时间. 相比前两种较为灵活.
-
User-Defined Filters
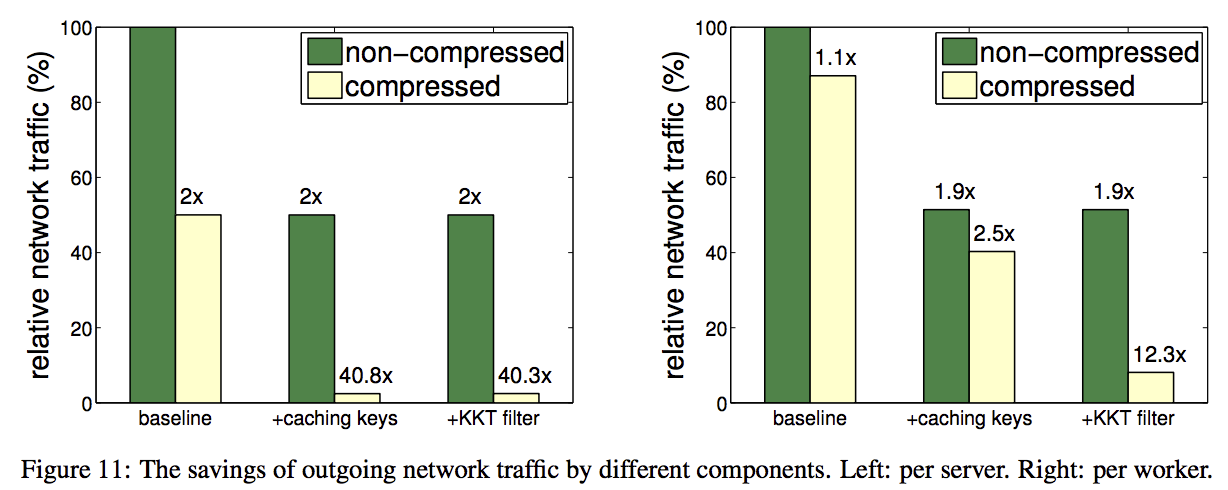
支持选择性地同步部分(key,value)pairs. 比如选择性地同步对weight影响最大的参数 (KKT filter等).
Implementation and evaluation
-
Implementation
Servers 使用一致性哈希存储(key,value)pairs; 对于 fault tolerance, 使用链式复制.
-
Evaluation
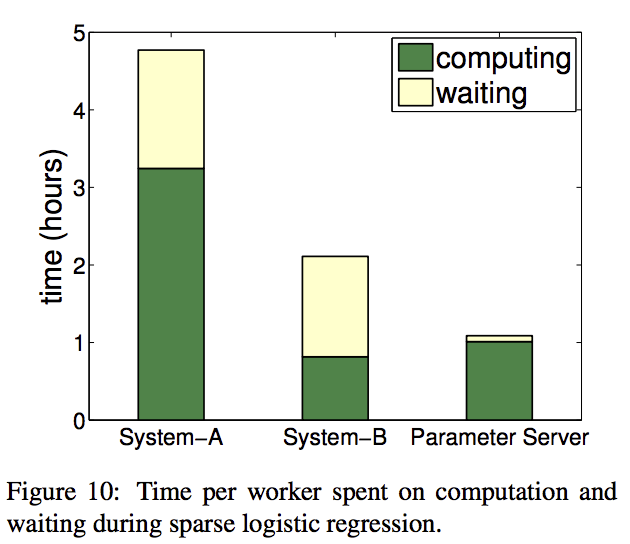
两个算法:Sparse Logistic Regression 和 LDA. Sketch.
参考文献
Scaling Distributed Machine Learning with the Parameter Server